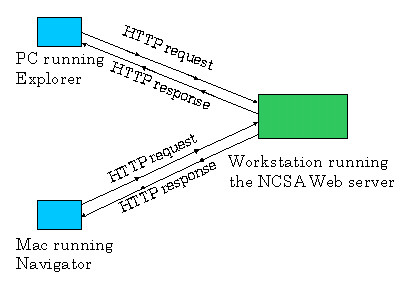
Figure 2.2-1: HTTP request-response behavior
History is sprinkled with the arrival of electronic communication technologies that have had major societal impacts. The first such technology was the telephone, invented in the 1870s. The telephone allowed two persons to orally communicate in real-time without being in the same physical location. It had a major impact on society -- both good and bad. The next electronic communication technology was broadcast radio/television, which arrived in the 1920s and 1930s. Broadcast radio/television allowed people to receive vast quantities of audio and video information. It also had a major impact on society -- both good and bad. The third major communication technology that has changed the way people live and work is the Web. Perhaps what appeals the most to users about the Web is that it is on demand. Users receive what they want, when they want it. This is unlike broadcast radio and television, which force users to "tune in" when the content provider makes the content available. In addition to being on demand, the Web has many other wonderful features that people love and cherish. It is enormously easy for any individual to make any available available over the Web; everyone can become a publisher at extremely low cost. Hyperlinks and search engines help us navigate through an ocean of Web sites. Graphics and animated graphics stimulate our senses. Forms, Java applets, Active X components, as well as many other devices enable us to interact with pages and sites. And more and more, the Web provides a menu interface to vast quantities of audio and video material stored in the Internet, audio and video that can be accessed on demand.
A Web page (also called a document) consists of objects. An object is a simply file -- such as a HTML file, a JPEG image, a GIF image, a Java applet, an audio clip, etc. -- that is addressable by a single URL. Most Web pages consist of a base HTML file and several referenced objects. For example, if a Web page contains HTML text and five JPEG images, then the Web page has six objects: the base HTML file plus the five images. The base HTML file references the other objects in the page with the objects' URLs. Each URL has two components: the host name of the server that houses the object and the object's path name. For example, the URL
HTTP defines how Web clients (i.e., browsers) request Web pages from servers (i.e., Web servers) and how servers transfer Web pages to clients. We discuss the interaction between client and server in detail below, but the general idea is illustrated in Figure 2.2-1. When a user requests a Web page (e.g., clicks on a hyperlink), the browser sends HTTP request messages for the objects in the page to the server. The server receives the requests and responds with HTTP response messages that contain the objects. Through 1997 essentially all browsers and Web servers implement version HTTP/1.0, which is defined in [RFC 1945]. Beginning in 1998 Web servers and browsers began to implement version HTTP/1.1, which is defined in [RFC 2068]. HTTP/1.1 is backward compatible with HTTP/1.0; a Web server running 1.1 can "talk" with a browser running 1.0, and a browser running 1.1 can "talk" with a server running 1.0.
Both HTTP/1.0 and HTTP/1.1 use TCP as their underlying transport protocol (rather than running on top of UDP). The HTTP client first initiates a TCP connection with the server. Once the connection is established, the browser and the server processes access TCP through their socket interfaces. As described in Section 2.1, on the client side the socket interface is the "door" between the client process and the TCP connection; on the server side it is the "door" between the server process and the TCP connection. The client sends HTTP request messages into its socket interface and receives HTTP response messages from its socket interface. Similarly, the HTTP server receives request messages from its socket interface and sends response messages into the socket interface. Once the client sends a message into its socket interface, the message is "out of the client's hands" and is "in the hands of TCP". Recall from Section 2.1 that TCP provides a reliable data transfer service to HTTP. This implies that each HTTP request message emitted by a client process eventually arrives in tact at the server; similarly, each HTTP response message emitted by the server process eventually arrives in tact at the client. Here we see one of the great advantages of a layered architecture - HTTP need not worry about lost data, or the details of how TCP recovers from loss or reordering of data within the network. That is the job of TCP and the protocols in the lower layers of the protocol stack.
TCP also employs a congestion control mechanism which we shall discuss in detail in Chapter 3. We only mention here that this mechanism forces each new TCP connection to initially transmit data at a relatively slow rate, but then allows each connection to ramp up to a relatively high rate when the network is uncongested. The initial slow-transmission phase is referred to as slow start.
It is important to note that the server sends requested files to clients without storing any state information about the client. If a particular client asks for the same object twice in a period of a few seconds, the server does not respond by saying that it just served the object to the client; instead, the server resends the object, as it has completely forgotten what it did earlier. Because an HTTP server maintains no information about the clients, HTTP is said to be a stateless protocol.
The steps above use non-persistent connections because each TCP connection is closed after the server sends the object -- the connection does not persist for other objects. Note that each TCP connection transports exactly one request message and one response message. Thus, in this example, when a user requests the Web page, 11 TCP connections are generated.
In the steps described above, we were intentionally vague about whether the client obtains the 10 JPEGs over ten serial TCP connections, or whether some of the JPEGs are obtained over parallel TCP connections. Indeed, users can configure modern browsers to control the degree of parallelism. In their default modes, most browsers open five to ten parallel TCP connections, and each of these connections handles one request-response transaction. If the user prefers, the maximum number of parallel connections can be set to one, in which case the ten connections are established serially. As we shall see in the next chapter, the use of parallel connections shortens the response time since it cuts out some of the RTT and slow-start delays. Parallel TCP connections can also allow the requesting browser to steal a larger share of its fair share of the end-to-end transmission bandwidth.
Before continuing, let's do a back of the envelope calculation to estimate the amount of time from when a client requests the base HTML file until the file is received by the client. To this end we define the round-trip time RTT, which is the time it takes for a small packet to travel from client to server and then back to the client. The RTT includes packet propagation delays, packet queuing delays in intermediate routers and switches, and packet processing delays. (These delays were discussed in Section 1.6.) Now consider what happens when a user clicks on a hyperlink. This causes the browser to initiate a TCP connection between the browser and the Web server; this involves a "three-way handshake" -- the client sends a small TCP message to the server, the server acknowledges and responds with a small message, and finally the client acknowledges back to the server. One RTT elapses after the first two parts of the three-way handshake. After completing the first two parts of the handshake, the client sends the HTTP request message into the TCP connection, and TCP "piggybacks" the last acknowledgment (the third part of the three-way handshake) onto the request message. Once the request message arrives at the server, the server sends the HTML file into the TCP connection. This HTTP request/response eats up another RTT. Thus, roughly, the total response time is 2RTT plus the transmission time at the server of the HTML file.
Persistent Connections
Non-persistent connections have some shortcomings. First, a brand new connection must be established and maintained for each requested object. For each of these connections, TCP buffers must be allocated and TCP variables must be kept in both the client and server. This can place a serious burden on the Web server, which may be serving requests from hundreds of different clients simultaneously. Second, as we just described, each object suffers two RTTs -- one RTT to establish the TCP connection and one RTT to request and receive an object. Finally, each object suffers from TCP slow start because every TCP connection begins with a TCP slow-start phase. However, the accumulation of RTT and slow start delays is partially alleviated by the use of parallel TCP connections.
With persistent connections, the server leaves the TCP connection open after sending responses. Subsequent requests and responses between the same client and server can be sent over the same connection. In particular, an entire Web page (in the example above, the base HTML file and the ten images) can be sent over a single persistent TCP connection; moreover, multiple Web pages residing on the same server can be sent over one persistent TCP connection. Typically, the HTTP server closes the connection when it isnt used for a certain time (the timeout interval), which is often configurable. There are two versions of persistent connections: without pipelining and with pipelining. For the version without pipelining, the client issues a new request only when the previous response has been received. In this case, each of the referenced objects (the ten images in the example above) experiences one RTT in order to request and receive the object. Although this is an improvement over non-persistent's two RTTs, the RTT delay can be further reduced with pipelining. Another disadvantage of no pipelining is that after the server sends an object over the persistent TCP connection, the connection hangs -- does nothing -- while it waits for another request to arrive. This hanging wastes server resources.
The default mode of HTTP/1.1 uses persistent connections with pipelining. In this case, the HTTP client issues a request as soon as it encounters a reference. Thus the HTTP client can make back-to-back requests for the referenced objects. When the server receives the requests, it can send the objects back-to-back. If all the requests are sent back-to-back and all the responses are sent back-to-back, then only one RTT is expended for all the referenced objects (rather than one RTT per referenced object when pipelining isn't used). Furthermore, the pipelined TCP connection hangs for a smaller fraction of time. In addition to reducing RTT delays, persistent connections (with or without pipelining) have a smaller slow-start delay than non-persistent connections. This is because that after sending the first object, the persistent server does not have to send the next object at the initial slow rate since it continues to use the same TCP connection. Instead, the server can pick up at the rate where the first object left off. We shall quantitatively compare the performance of non-persistent and persistent connections in the homework problems of Chapter 3. The interested reader is also encouraged to see [Heidemann 1997] and [Nielsen 1997].
We can learn a lot my taking a good look at this simple request message. First of all, we see that the message is written in ordinary ASCII text, so that your ordinary computer-literate human being can read it. Second, we see that the message consists of five lines, each followed by a carriage return and a line feed. The last line is followed by an additional carriage return and line feed. Although this particular request message has five lines, a request message can have many more lines or as little as one line. The first line of a HTTP request message is called the request line; the subsequent lines are called the header lines. The request line has three fields: the method field, the URL field, and the HTTP version field. The method field can take on several different values, including GET, POST, and HEAD. The great majority of HTTP request messages use the GET method. The GET method is used when the browser requests an object, with the requested object identified in the URL field. In this example, the browser is requesting the object /somedir/page.html. (The browser doesn't have to specify the host name in the URL field since the TCP connection is already connected to the host (server) that serves the requested file.) The version is self-explanatory; in this example, the browser implements version HTTP/1.1.
Now let's look at the header lines in the example. By including the Connection:close header line, the browser is telling the server that it doesn't want to use persistent connections; it wants the server to close the connection after sending the requested object. Thus the browser that generated this request message implements HTTP/1.1 but it doesn't want to bother with persistent connections. The User-agent: header line specifies the user agent, i.e., the browser type that is making the request to the server . Here the user agent is Mozilla/4.0, a Netscape browser. This header line is useful because the server can actually send different versions of the same object to different types of user agents. (Each of the versions is addressed by the same URL.) The Accept: header line tells the server the type of objects the browser is prepared to accept. In this case, the client is prepared to accept HTML text, a GIF image or a JPEG image. If the file /somedir/page.html contains a Java applet (and who says it can't!), then the server shouldn't send the file, since the browser can not handle that object type. Finally, the Accept-language: header indicates that the user prefers to receive a French version of the object, if such an object exists on the server; otherwise, the server should send its default version.
Having looked at an example, let us now look at the general format for a request message, as shown in Figure 2.2-2:
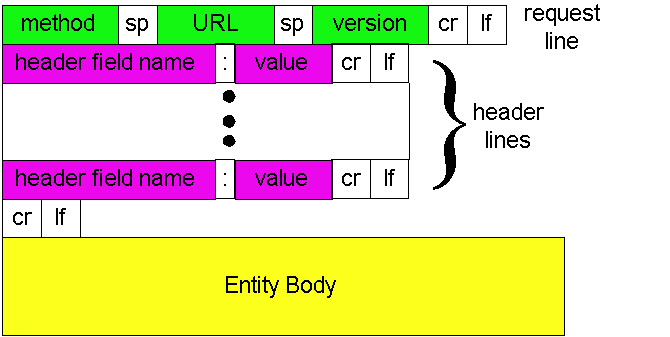
We see that the general format follows closely the example request message above. You may have noticed, however, that after the header lines (and the additional carriage return and line feed) there is an "Entity Body". The Entity Body is not used with the GET method, but is used with the POST method. The HTTP client uses the POST method when the user fills out a form -- for example, when a user gives search words to a search engine such as Yahoo. With a POST message, the user is still requesting a Web page from the server, but the specific contents of the Web page depend on what the user wrote in the form fields. If the value of the method field is POST, then the entity body contains what the user typed into the form fields. The HEAD method is similar to the POST method. When a server receives a request with the HEAD method, it responds with an HTTP message but it leaves out the requested object. The HEAD method is often used by HTTP server developers for debugging.
HTTP Response Message
Below we provide a typical HTTP response message. This response message could be the response to the example request message just discussed.
Now let's look at the header lines. The server uses the Connection: close header line to tell the client that it is going to close the TCP connection after sending the message. The Date: header line indicates the time and date when the HTTP response was created and sent by the server. Note that this is not the time when the object was created or last modified; it is the time when the server retrieves the object from its file system, inserts the object into the response message and sends the response message. The Server: header line indicates that the message was generated by an Apache Web server; it is analogous to the User-agent: header line in the HTTP request message. The Last-Modified: header line indicates the time and date when the object was created or last modified. The Last-Modified: header, which we cover in more detail below, is critical for object caching, both in the local client and in network cache (a.k.a. proxy) servers. The Content-Length: header line indicates the number of bytes in the object being sent. The Content-Type: header line indicates that the object in the entity body is HTML text. (The object type is officially indicated by the Content-Type: header and not by the file extension.)
Note that if the server receives an HTTP/1.0 request, it will not use
persistent connections, even if it is an HTTP/1.1 server. Instead the HTTP/1.1
server will close the TCP connection after sending the object. This is
necessary because an HTTP/1.0 client expects the server to close the connection.
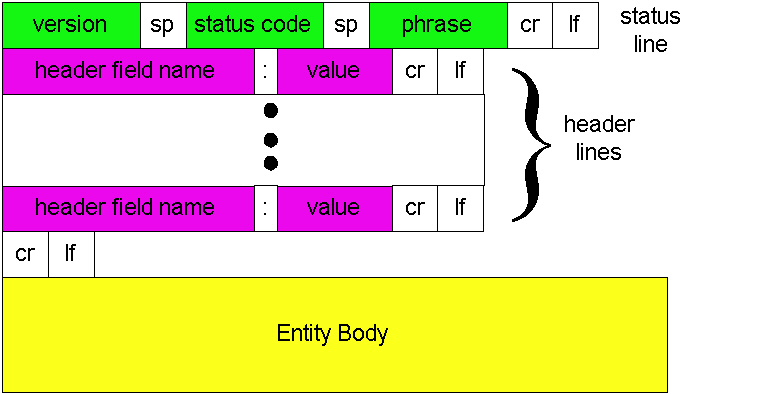
Figure 2.2-3: General format of a response message
Having looked at an example, let us now examine the general format of a response message, which is shown in Figure 2.2-3. This general format of the response message matches the previous example of a response message. Let's say a few additional words about status codes and their phrases. The status code and associated phrase indicate the result of the request. Some common status codes and associated phrases include:
telnet
www.eurecom.fr 80
GET /~ross/index.html
HTTP/1.0
(Hit the carriage return twice after typing the second line.) This opens a TCP connection to port 80 of the host www.eurecom.fr and then sends the HTTP GET command. You should see a response message that includes the base HTML file of Professor Ross's homepage. If you'd rather just see the HTTP message lines and not receive the object itself, replace GET with HEAD. Finally, replace /~ross/index.html with /~ross/banana.html and see what kind of response message you get.
In this section we discussed a number of header lines that can be used within HTTP request and response messages. The HTTP specification (especially HTTP/1.1) defines many, many more header lines that can be inserted by browsers, Web servers and network cache servers. We have only covered a small fraction of the totality of header lines. We will cover a few more below and another small fraction when we discuss network Web caching at the end of this chapter. A readable and comprehensive discussion of HTTP headers and status codes is given in [Luotonen 1998]. An excellent introduction to the technical issues surrounding the Web is [Yeager 1996].
How does a browser decide which header lines it includes in a request
message? How does a Web server decide which header lines it includes in
a response messages? A browser will generate header lines as a function
of the browser type and version (e.g., an HTTP/1.0 browser will not generate
any 1.1 header lines), user configuration of browser (e.g., preferred language)
and whether the browser currently has a cached, but possibly out-of-date,
version of the object. Web servers behave similarly: there are different
products, versions, and configurations, all of which influence which header
lines are included in response messages.
We will see in Chapter 7 that HTTP performs a rather weak form of authentication, one that would not be difficult to break. We will study more secure and robust authentication schemes later in Chapter 7.
Web servers use cookies for many different purposes:
Although Web caching can reduce user-perceived response times, it introduces a new problem -- a copy of an object residing in the cache may be stale. In other words, the object housed in the Web server may have been modified since the copy was cached at the client. Fortunately, HTTP has a mechanism that allows the client to employ caching while still ensuring that all objects passed to the browser are up-to-date. This mechanism is called the conditional GET. An HTTP request message is a so-called conditional GET message if (i) the request message uses the GET method and (ii) the request message includes an If-Modified-Since:header line.
To illustrate how the conditional GET operates, let's walk through an example. First, a browser requests an uncached object from some Web server:

So why bother with a Web cache? What advantages does it have? Web caches are enjoying wide-scale deployment in the Internet for at least three reasons. First, a Web cache can substantially reduce the response time for a client request, particularly if the bottleneck bandwidth between the client and the origin server is much less than the bottleneck bandwidth between the client and the cache. If there is a high-speed connection between the client and the cache, as there often is, and if the cache has the requested object, then the cache will be able to rapidly deliver the object to the client. Second, as we will soon illustrate with an example, Web caches can substantially reduce traffic on an institution's access link to the Internet. By reducing traffic, the institution (e.g., a company or a university) does not have to upgrade bandwidth as quickly, thereby reducing costs. Furthermore, Web caches can substantially reduce Web traffic in the Internet as a whole, thereby improving performance for all applications. In 1998, over 75% of Internet traffic was Web traffic, so a significant reduction in Web traffic can translate into a significant improvement in Internet performance [Claffy 1998]. Third, an Internet dense with Web caches -- e.g., at institutional, regional and national levels -- provides an infrastructure for rapid distribution of content, even for content providers who run their sites on low-speed servers behind low-speed access links. If such a "resouce-poor" content provider suddenly has popular content to distribute, this popular content will quickly be copied into the Internet caches, and high user demand will be satisfied.
To gain a deeper understanding of the benefits of caches, let us consider an example in the context of Figure 2.2-5. In this figure, there are two networks - the institutional network and the Internet. The institutional network is a high-speed LAN. A router in the institutional network and a router in the Internet are connected by a 1.5 Mbps link. The institutional network consists of a high-speed LAN which is connected to the Internet through a 1.5 Mbps access link. The origin servers are attached to the Internet, but located all over the globe. Suppose that the average object size is 100 Kbits and that the average request rate from the institution's browsers to the origin servers is 15 requests per second. Also suppose that amount of time it takes from when the router on the Internet side of the access link in Figure 2.2-5 forwards an HTTP request (within an IP datagram) until it receives the IP datagram (typically, many IP datagrams) containing the corresponding response is two seconds on average. Informally, we refer to this last delay as the "Internet delay".
The total response time -- that is the time from when a browser requests an object until the browser receives the object -- is the sum of the LAN delay, the access delay (i.e., the delay between the two routers) and the Internet delay. Let us now do a very crude calculation to estimate this delay. The traffic intensity on the LAN (see Section 1.6) is
whereas the traffic intensity on access link (from Internet router to institution router) is
A traffic intensity of .15 on a LAN typically results in at most tens of milliseconds of delay; hence, we can neglect the LAN delay. However, as discussed in Section 1.6, as the traffic intensity approaches 1 (as is the case of the access link in Figure 2.2-5), the delay on a link becomes very large and grows without bound. Thus, the average response time to satisfy requests is going to be on the order of minutes, if not more, which is unacceptable for the institution's users. Clearly something must be done.
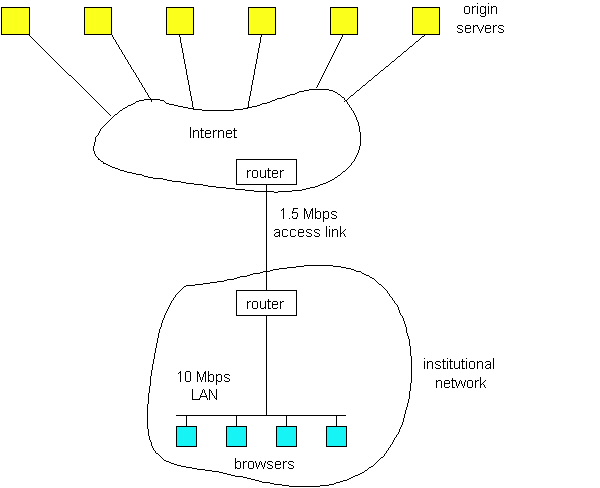
One possible solution is to increase the access rate from 1.5 Mbps to, say, 10 Mbps. This will lower the traffic intensity on the access link to .15, which translates to negligible delays between the two routers. In this case, the total response response time will roughly be 2 seconds, that is, the Internet delay. But this solution also means that the institution must upgrade its access link from 1.5 Mbps to 10 Mbps, which can be very costly.
Now consider the alternative solution of not upgrading the access link but instead installing a Web cache in the institutional network. This solution is illustrated in Figure 2.2-6. Hit rates -- the fraction of requests that are satisfied by a cache -- typically range from .2 to .7 in practice. For illustrative purposes, let us suppose that the cache provides a hit rate of .4 for this institution. Because the clients and the cache are connected to the same high-speed LAN, 40% of the requests will be satisfied almost immediately, say within 10 milliseconds, by the cache. Nevertheless, the remaining 60% of the requests still need to be satisfied by the origin servers. But with only 60% of the requested objects passing through the access link, the traffic intensity on the access link is reduced from 1.0 to .6 . Typically a traffic intensity less than .8 corresponds to a small delay , say tens of milliseconds, on a 1.5 Mbps link, which is negligible compared with the 2 second Internet delay. Given these considerations, average delay therefore is
.4*(0.010 seconds) + .6*(2.01 seconds)
which is just slightly larger than 2.1 seconds. Thus, this second solution provides an even lower response time then the first solution, and it doesn't require the institution to upgrade its access rate. The institution does, of course, have to purchase and install a Web cache. But this cost is low -- many caches use public-domain software that run on inexpensive servers and PCs.

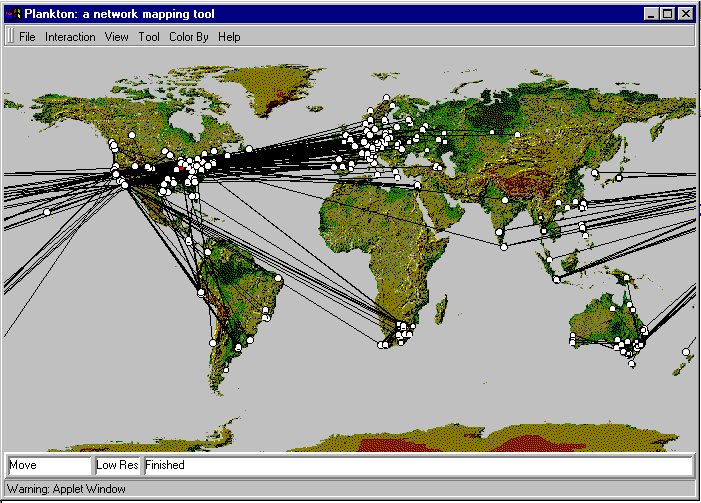
An example of cooperative caching system is the NLANR caching system, which consists of a number of backbone caches in the US providing service to institutional and regional caches from all over the globe [NLANR]. The NLANR caching hierarchy is shown in Figure 2.2-7 [Huffaker 1998]. The caches obtain objects from each other using a combination of HTTP and ICP (Internet Caching Protocol). ICP is an application-layer protocol that allows one cache to quickly ask another cache if it has a given document [RFC 2186]; a cache can then use HTTP to retrieve the object from the other cache. ICP is used extensively in many cooperative caching systems, and is fully supported by Squid, a popular public-domain software for Web caching [Squid]. If you are interested in learning more about ICP, you are encouraged to see [Luotonen 1998] [Ross 1998] and the ICP RFC [RFC 2186].
An alternative form of cooperative caching involves clusters of caches, often co-located on the same LAN. A single cache is often replaced with a cluster of caches when the single cache is not sufficient to handle the traffic or provide sufficient storage capacity. Although cache clustering is a natural way to scale as traffic increases, they introduce a new problem: When a browser wants to request a particular object, to which cache in the cache cluster should it send the request? This problem can be elegantly solved using hash routing (If you are not familiar with hash functions, you can read about them in Chapter 7.) In the simplest form of hash routing, the browser hashes the URL, and depending on the result of the hash, the browser directs its request message to one of the caches in the cluster. By having all the browsers use the same hash function, an object will never be present in more than one cache in the cluster, and if the object is indeed in the cache cluster, the browser will always direct its request to the correct cache. Hash routing is the essence of the Cache Array Routing Protocol (CARP). If you are interested in learning more about hash routing or CARP, see [Valloppillil 1997], [Luotonen 1998], [Ross 1998] and [Ross 1997].
Web caching is a rich and complex subject; over two thirds (40 pages)
of the HTTP/1.1 RFC is devoted to Web caching [RFC
2068]! Web caching has also enjoyed extensive research and product
development in recent years. Furthermore, caches are now being built to
handle streaming audio and video. Caches will likely play an important
role as the Internet begins to provide an infrastructure for the large-scale,
on-demand distribution of music, television shows and movies in the Internet.
[Claffy 1998] K. Claffy, G. Miller
and K. Thompson, "The Nature of the Beast: Recent Traffic Measurements
from the Internet Backbone, CAIDA Web site, http://www.caida.org/Papers/Inet98/index.html,
1998.
[Heidemann 1997] J. Heidemann,
K. Obraczka and J. Touch, Modeling the Performance of HTTP Over Several
Transport Protocols," IEEE/ACM Transactions on Networking, Vol. 5, No.
5, October 1997, pp. 616-630.
[Huffaker 1998] B. Huffaker, J. Jung,
D. Wessels and K. Claffy, Visualization of the Growth and Topology of the
NLANR Caching Hierarchy, http://squid.nlanr.net/Squid/ http://www.caida.org/Tools/Plankton/Paper/plankton.html
, 1998.
[Luotonen 1998] A. Luotonen,
"Web Proxy Servers," Prentice Hall, New Jersey, 1998.
[Netcraft] Survey of Web Server Penetration,
Netcraft Web Site, http://www.netcraft.com/Survey/
[NLANR] A Distributed Testbed for National
Information Provisioning, http://ircache.nlanr.net
.
[Nielsen 1997] H. F. Nielsen, J.
Gettys, A. Baird-Smith, E. Prud'hommeaux, H.W. Lie, C. Lilley, Network
Performance Effects of HTTP/1.1, CSS1, and PNG, W3C Document, 1997
(also appeared in SIGCOMM' 97).
[RFC 1945] T. Berners-Lee, R. Fielding,
and H. Frystyk, "Hypertext Transfer Protocol -- HTTP/1.0," [RFC
1945], May 1996.
[RFC 2068] R. Fielding, J. Gettys,
J. Mogul, H. Frystyk, and T. Berners-Lee, "Hypertext Transfer Protocol
-- HTTP/1.1," [RFC
2068], January 1997
[RFC 2109] D. Kristol and L. Montulli,
"HTTP State Management Mechanism," [RFC
2109], February 1997.
[RFC 2186] K. Claffy and D. Wessels,
"Internet Caching Protocol (ICP), version 2," [RFC
2186], September 1997.
[Ross 1997] K.W. Ross, "Hash-Routing for
Collections of Shared Web Caches," IEEE Network
Magazine, Nov-Dec 1997
[Ross 1998] K.W. Ross, Distribution
of Stored Information in the Web, A Online Tutorial, http://www.eurecom.fr/~ross/CacheTutorial/DistTutorial.html,
1998.
[Squid] Squid Internet Object Cache, http://squid.nlanr.net/Squid/
[Valloppillil 1997] V. Valloppillil
and K.W. Ross, "Cache Array Routing Protocol," Internet Draft, <draft-vinod-carp-v1-03.txt>,
June 1997.
[Yeager 1996] N.J. Yeager and R.E. McGrath,
"Web Server Technology," Morgan Kaufmann Publishers, San Francisco, 1996.
If you are interested in an Internet Draft relating to a certain subject or protocol enter the keyword(s) here.